React源码学习进阶(二)初识Fiber架构
本文采用React v16.13.1版本源码进行分析
什么是Fiber
我们知道React团队在16版本重写了整个reconciler架构,将之前的stack版本改为了fiber版本,这个过程React团队经历了2年时间,可以说是非常大的一个更新了。
Fiber架构最大的不同是支持了async rendering,后来React团队将这个特性改名为concurrent,在16版本和17版本默认都没有走,在最新的18版本终于成了默认策略。
为什么React团队需要支持这一个特性呢?我想这幅图应该是最清晰能够解释的:
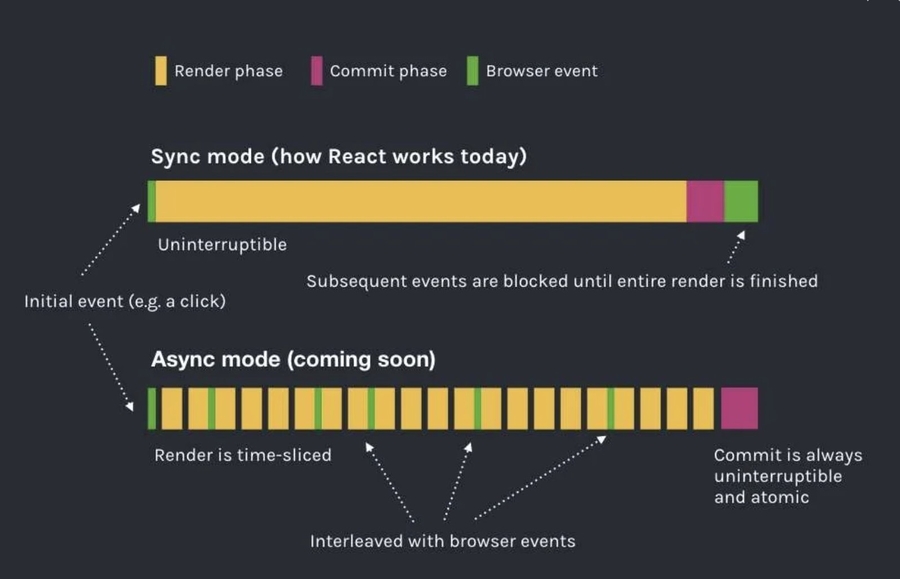
React的渲染,我们可以简单分为几个阶段:
Render阶段,这个是之前进行reconcile的阶段,可能也是最耗时的阶段。
commit阶段,也就是最终的DOM操作,通过之前的源码分析我们知道它都是在最后统一执行。
浏览器事件响应,实际上由于GUI的渲染线程和JS引擎线程是互斥的,如果前面render阶段占用过长时间,会导致浏览器渲染的卡顿(尤其是动画渲染会有明显的感知),另外事件队列也需要等待JS引擎空闲时才能执行,所以用户的事件也是无法得到响应的。
所以归纳一下React团队实现Fiber架构的最大原因还是以下两点:
render时间太长,阻塞界面渲染(尤其是需要帧率的动画渲染)(原因:浏览器GUI线程与JS引擎线程互斥)
render时间太长,用户操作无法得到及时响应(原因:浏览器事件循环需要等待JS引擎线程的空闲才能执行)
再仔细剖析下Fiber架构如何解决上述问题:
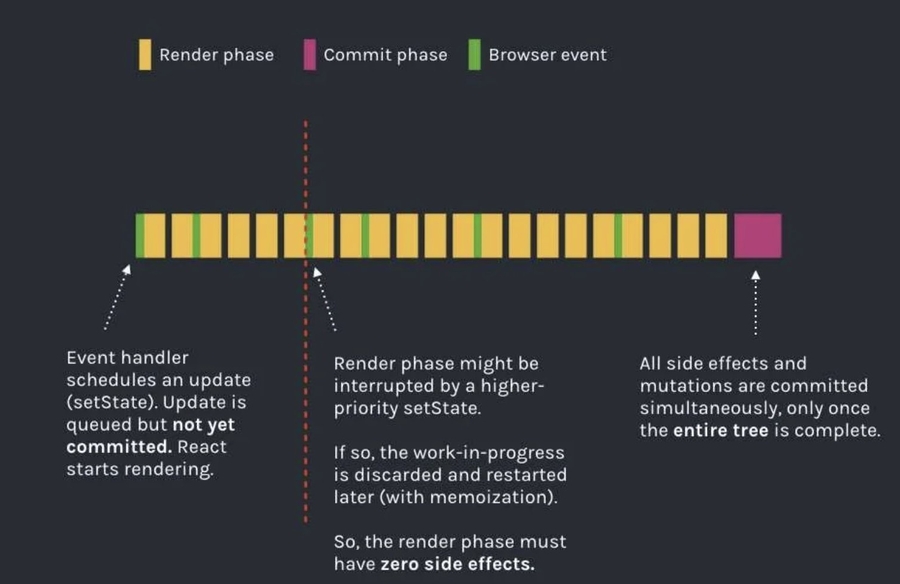
可以看到一开始render是由事件回调产生的,而在中间会有更高优先级的事件到来,开启了新的render,这就让用户事件、渲染都能得到快速响应。render阶段具体为什么能变成可切分的时间分片技术,后续文章会做深度剖析。
要保证render阶段是可以被打断切分的,一个非常重要的前提就是render过程中不能有副作用,也就是side effects,所以React就在render过程中将所有的side effects进行标记,最后通过一个不可打断的同步commit阶段来执行。
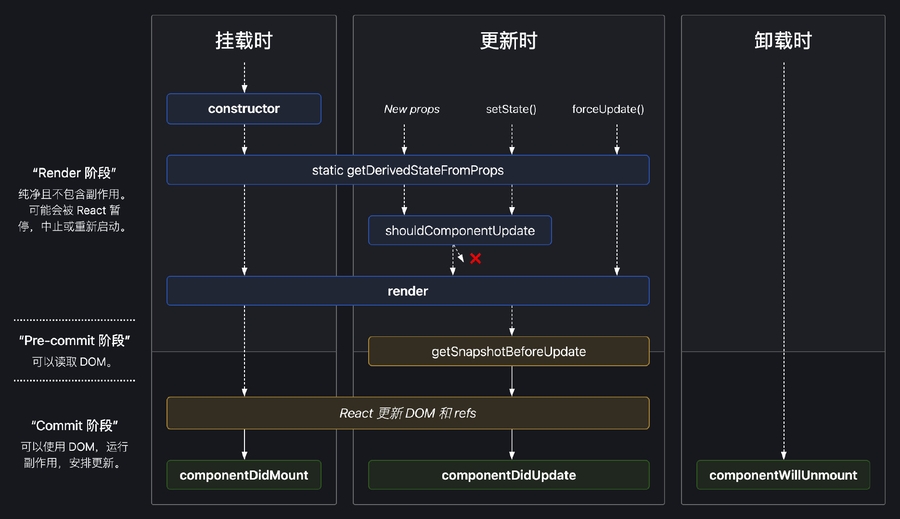
而这套机制也导致了React生命周期的变化:
Fiber的数据结构
Fiber不仅仅代表React架构,它还代表着React底层的数据结构。还记得我们之前分析过程中的Virtual DOM吗,之前是由每个JSX Element组成整个树,而在Fiber重构的架构下,可以理解为它是由一个个的Fiber Node组成的一个Fiber Tree。
实际上,Fiber这套数据结构,目的就是为了模拟栈,因为在之前的递归架构里面实际上是通过栈的方式去进行reconcile,通过递归栈来获取当前的virtual DOM和上下文,在fiber架构中,则是通过由fiber节点组成的链表结构来模拟这个栈。
让我们来对比一下它和栈的字段相似之处:
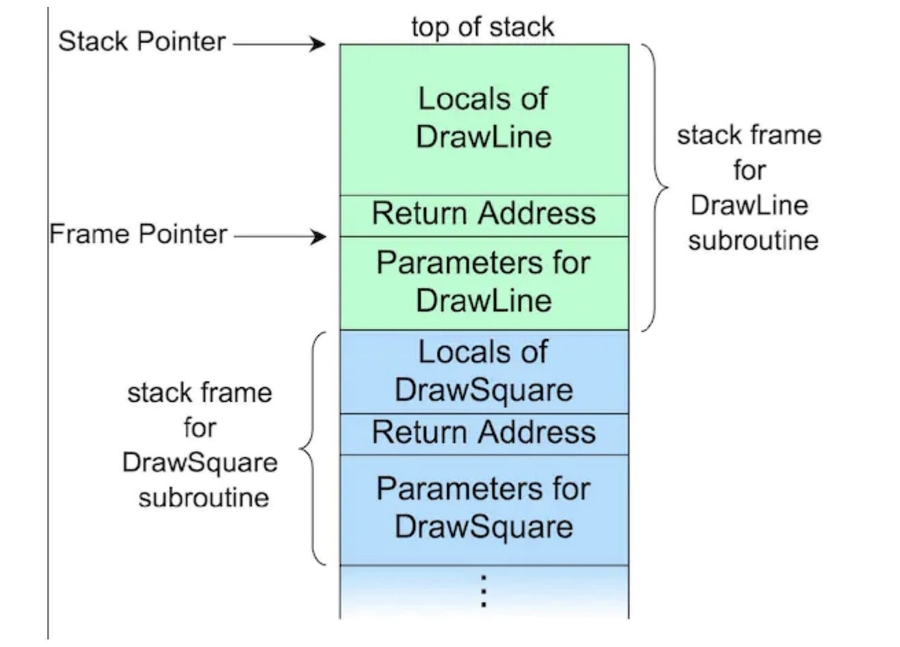
上面是一个典型的对战存储空间,可以做一个关联映射:
基本单位:栈是一个函数,而Fiber是一个FiberNode。
输入:栈是函数的入参,而Fiber是
Props本地状态:栈是函数的本地变量,而Fiber是
stateNode输出:栈是函数的返回值,而Fiber是
React Element(其中函数存储在type字段上)下级:栈是函数的嵌套调用,而Fiber是
child上级引用:栈是返回地址,而Fiber是
return
于是整个Fiber就形成了一个链表结构:
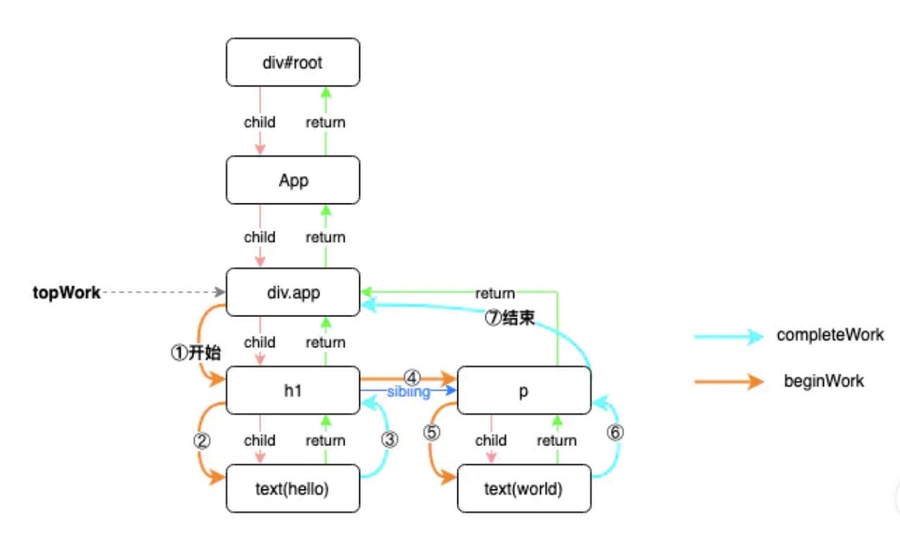
而我们每次render的过程,则是对上述的Fiber Tree(双向链表)做深度遍历的过程:
前序遍历,执行
beginWork,会进行reconcile的过程。后续遍历,会执行
completeWork,同时对兄弟节点展开深度遍历。
双缓存技术
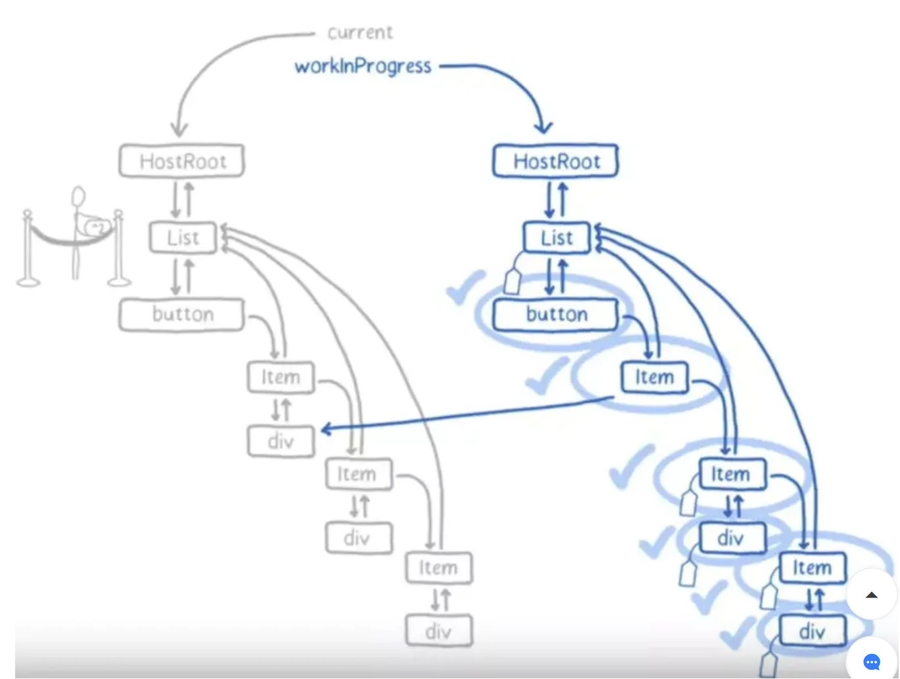
在Fiber更新过程中React使用到了Double Buffering,一般图形引擎就会采用这类技术,将图片绘制到缓冲区,再一次性传递给屏幕。
在React的Fiber实现中,一个Fiber节点挂载了alternate属性,指向了一个拷贝的Fiber节点,在更新过程中,当前渲染的节点称为current,而我们正在执行更新的节点称为WIP(workInProgress),通过对WIP节点的操作,以减少内存分配和垃圾回收。
Dan之前用了一个形象的比喻,可以将WIP想象为从旧的树中fork出来的分支,无论你对这个fork的版本做了什么,它都不会再影响到旧的树,而在真正完成这些操作后,再将WIP给commit回去,替换掉当前的current。
这个机制也让Error处理变的更加的简单,因为我们当前的current还保留着最正确的渲染版本,即使发生了异常,我们还可以继续沿用旧的节点。
关于Fiber的学习顺序
Fiber这套架构,解决了性能问题,同时也为后面的hooks的实现带来了便利。但是这套架构可以说十分复杂,React团队历时2年才将其完成,足见它的复杂性有多高,因此在学习Fiber的时候,建议从以下顺序来入手:
先学习
Sync模式学习Fiber数据结构与Root的渲染
Render阶段的beginWorkRender阶段的completeWorkcommit阶段hook的实现调度优先级算法实现
workloop与时间分片concurrent模式与中断
因为React团队对reconcile是一次比较大的重构,所以我们不必上来就一头扎进调度里面,调度的过程十分复杂,涉及较多前置知识和计算,在优先级方面先后从expirationTime换成了Lane的模型,整体来说可以先跳过这部分的实现。
先从sync模式中可以了解到整个Fiber的架构理念,对比和之前的模式的不同,在对render和commit有了足够的了解之后,再去进行concurrent的研究是我认为更好地学习步骤,后续文章也会按照这个顺序来进行写作。
Last updated